
High Availability Zonal Load Balancing (HAZL)
High Availability Zonal Load Balancing (HAZL) is a dynamic request-level load balancer in Buoyant Enterprise for Linkerd that balances HTTP and gRPC traffic in environments with multiple availability zones. For Kubernetes clusters deployed across multiple zones, HAZL can dramatically reduce cloud spend by minimizing cross-zone traffic.
Unlike other zone-aware options that use Kubernetes’s native Topology Aware Routing feature (including open source Linkerd), HAZL never sacrifices reliability to achieve this cost reduction.
In multi-zone environments, HAZL can:
- Cut cloud spend by eliminating cross-zone traffic both within and across cluster boundaries;
- Improve system reliability by distributing traffic to additional zones as the system comes under stress;
- Prevent failures before they happen by quickly reacting to increases in latency before the system begins to fail; and
- Preserve zone affinity for cross-cluster calls, allowing for cost reduction in multi-cluster environments.
Like Linkerd itself, HAZL is designed to “just work”. It can be applied to any Kubernetes service that speaks HTTP / gRPC regardless of the number of endpoints or distribution of workloads and traffic load across zones, and in the majority of cases requires no tuning or configuration.
HAZL vs Topology Aware Routing
HAZL was designed in response to limitations seen by customers using Kubernetes’s native Topology Aware Routing feature (formerly Topology Aware Hints). These limitations are shared by native Kubernetes balancing (kubeproxy) as well as systems such as open source Linkerd and Istio that make use of Topology Hints to make routing decisions.
Within these systems, the endpoints for each service are allocated ahead of time to specific zones by the Topology Aware Routing mechanism. This distribution is done at the Kubernetes API level, and attempts to allocate endpoints within the same zone (but note this behavior isn’t guaranteed, and the Topology Aware Routing mechanism may allocate endpoints from other zones). Once this allocation is done, it is static until endpoints are added or removed. It does not take into account traffic volumes, latency, or service health (except indirectly, if failing endpoints get removed via health checks).
Systems that make use of Topology Aware Routing, including Linkerd and Istio, use this allocation to decide where to send traffic. This accomplishes the goal of keeping traffic within a zone but at the expense of reliability: Topology Aware Routing itself provides no mechanism for sending traffic across zones if reliability demands it. The closest approximation in (some of) these systems are manual failover controls that allow the operator to failover traffic to a new zone.
Finally, Topology Aware Routing has a set of well-known constraints, including:
- It does not work well for services where a large proportion of traffic originates from a subset of zones.
- It does not take into account tolerations, unready nodes, or nodes that are marked as control plane or master nodes.
- It does not work well with autoscaling. The autoscaler may not respond to increases in traffic, or respond by adding endpoints in other zones.
- No affordance is made for cross-cluster traffic.
Take a deeper look into Topology Aware Routing in our blog post: The trouble with Topology Aware Routing: Sacrificing reliability in the name of cost savings.
Comparison of load balancing techniques
Stock Kubernetes
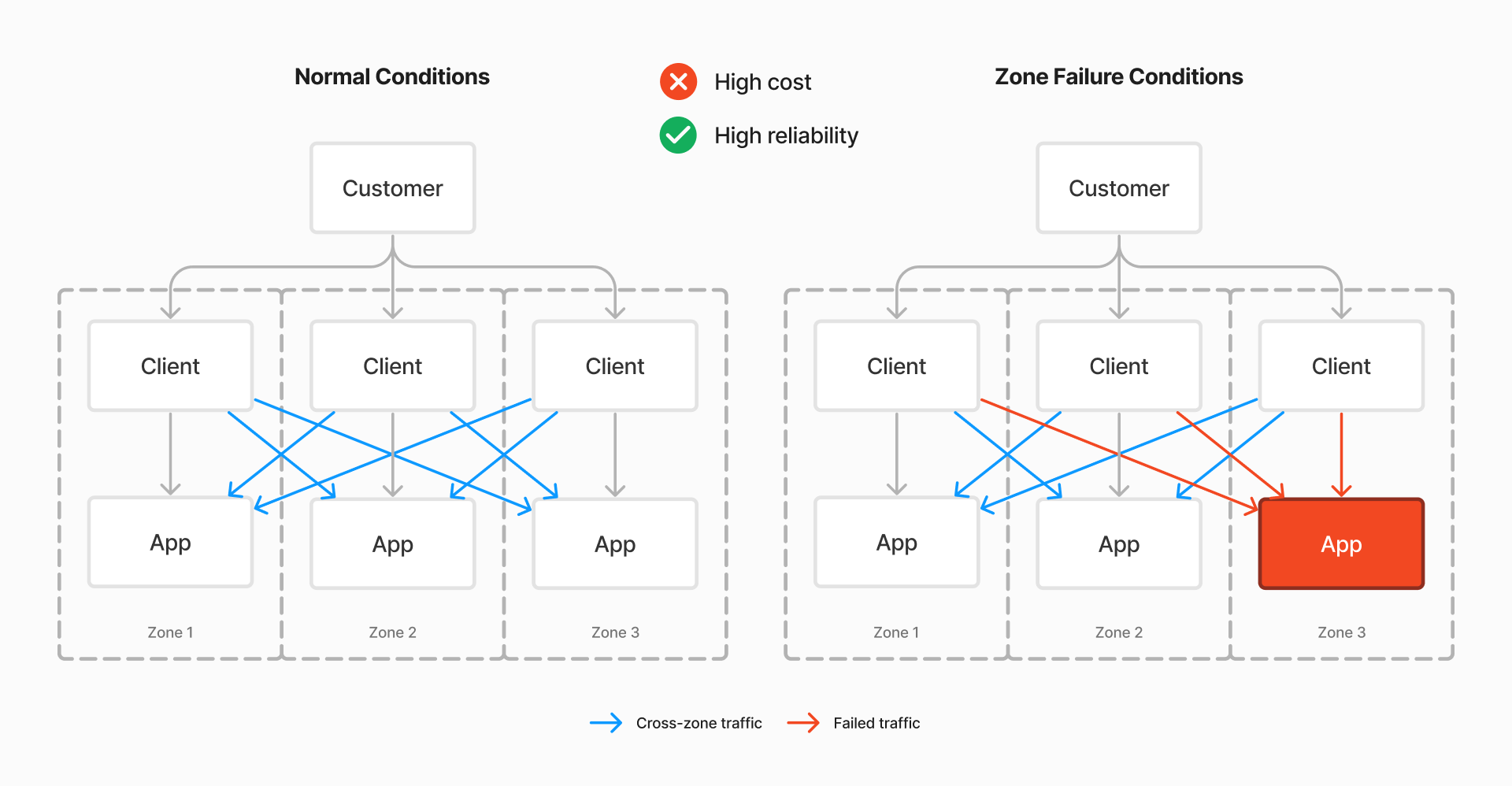
With stock Kubernetes (pictured above), traffic is always sent to all pods, regardless of zone. This has the advantage that under zone failure conditions, system reliability is preserved, as clients can reach out across zones. However, it also means that in normal conditions, cross-zone traffic (pictured in orange) is always used, incurring needless cloud spend.
Topology Hints
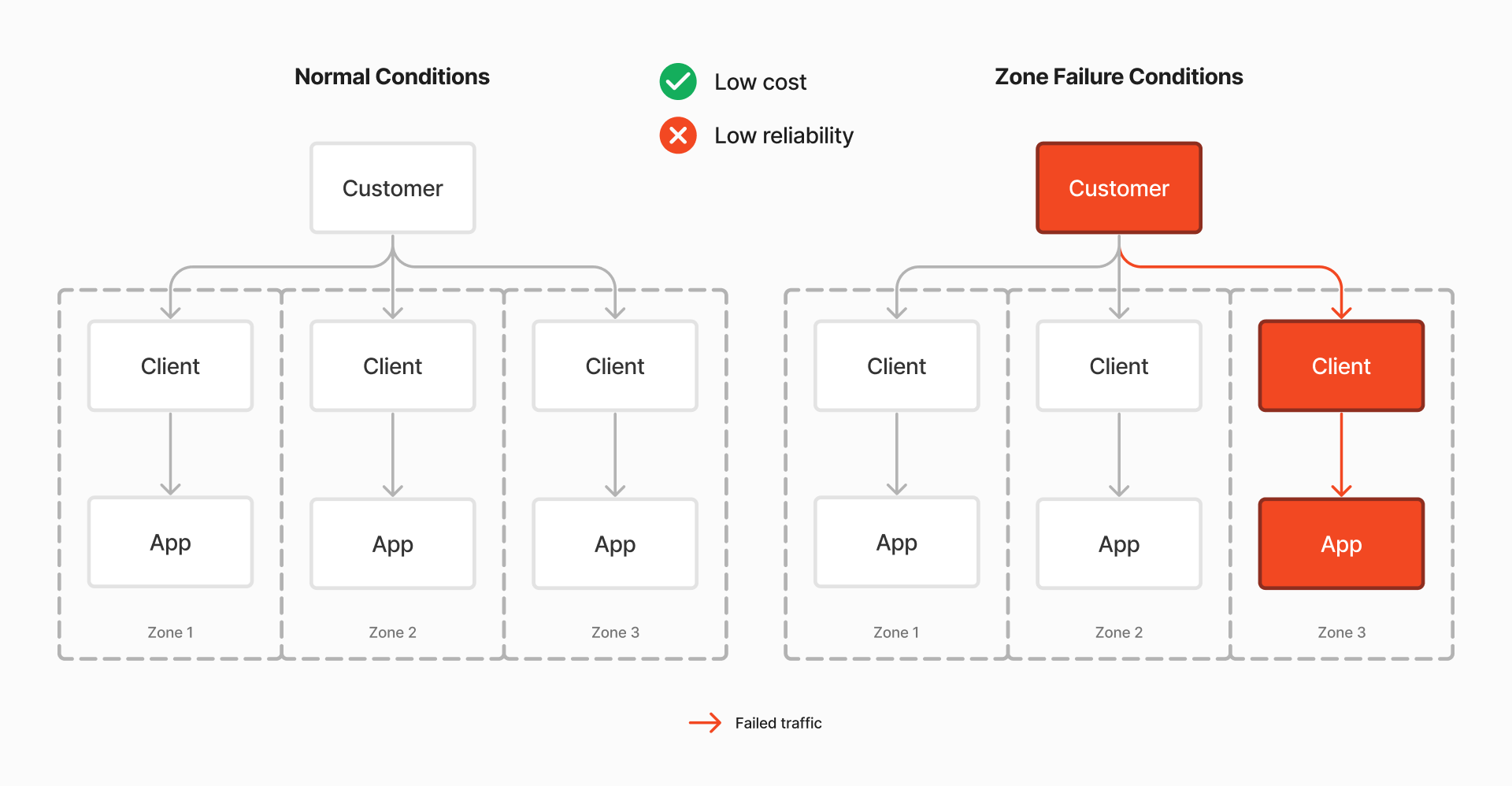
In a system with Topology Hints (aka Topology-aware Routing) enabled, traffic is restricted to the same zone. (With many exceptions and idiosyncrasies; see e.g. Safeguards for conditions under which Topology Hints will not apply.) This has the advantage that under normal conditions, cross-zone traffic is avoided and cloud spend is reduced. However, under zone failure conditions, clients cannot access applications in other zones, which means that such failures can impact customers.
High-availability Zonal Load Balancing (HAZL)
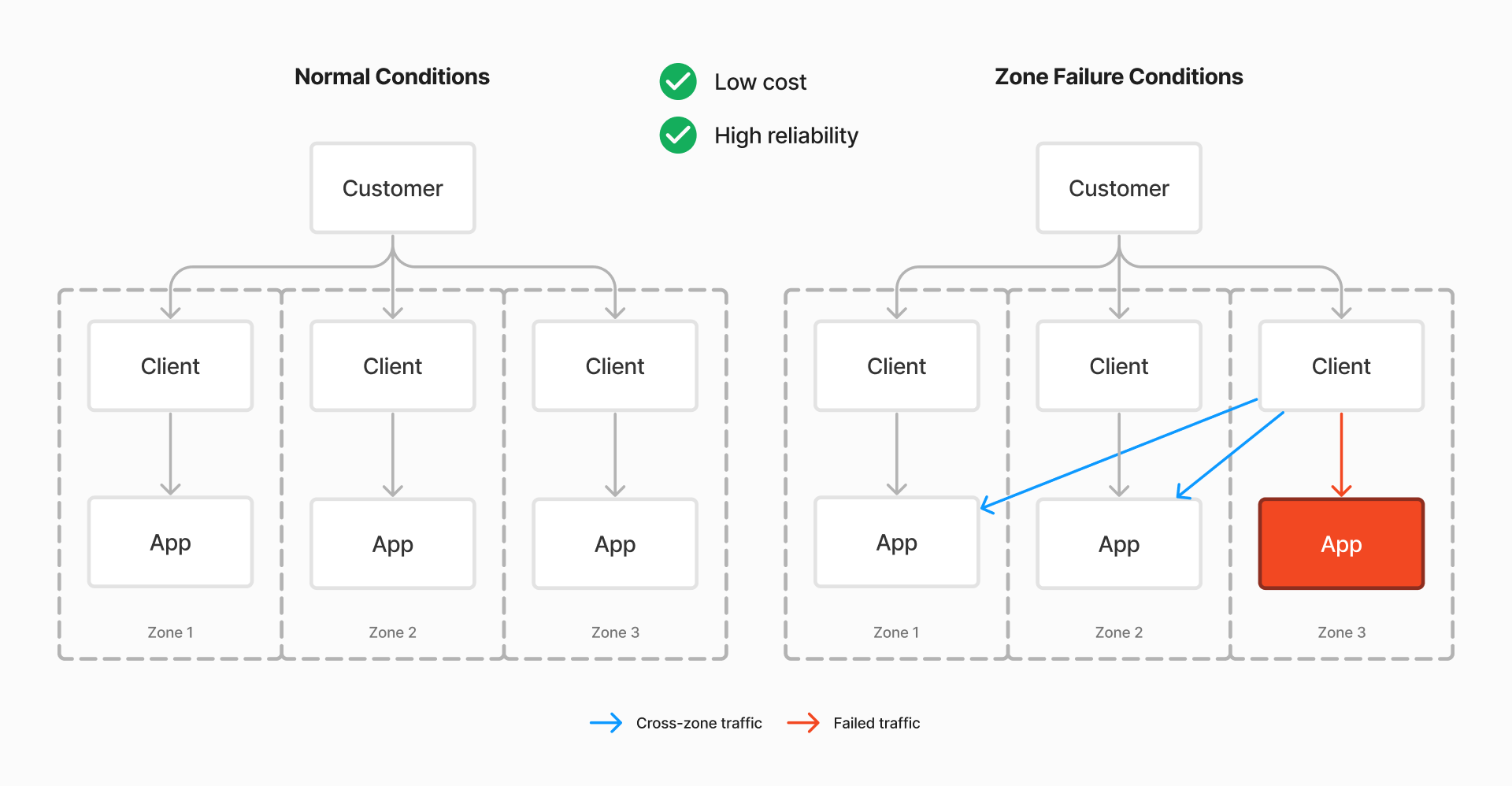
With high-availability zonal load balancing, you get the best of both worlds. Under normal conditions, traffic is kept within the same zone, reducing cloud spend. When the system is under stress, cross-zone traffic is allowed, maintaining overall reliability. As the system returns to normal, traffic is shifted back to the same zone.
Cross-cluster communication
For communication between Kubernetes clusters in the same region, while Topology Hints approaches lose zone information when sending traffic across clusters, HAZL instead will preserve the zone across cluster boundaries. This further allows for further reductions in cloud spend for multi-cluster environments.
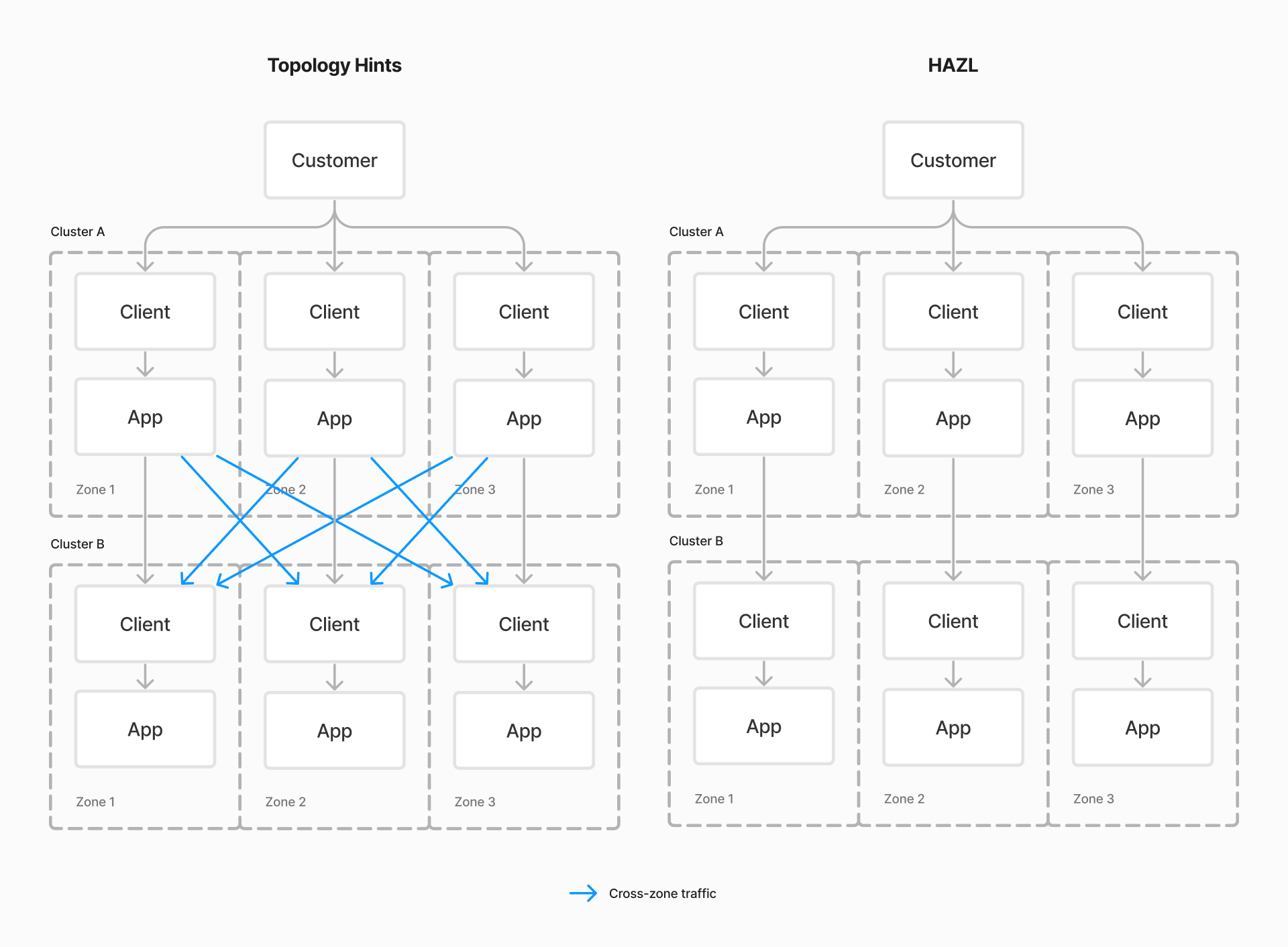
With Topology Hints approaches (pictured on the left), including open source Linkerd and Istio, traffic across cluster boundaries is balanced across all pods, regardless of zone. This means that in normal conditions, cross-zone traffic (pictured in orange) is always used, incurring needless cloud spend. With HAZL (pictured on the right), cross-cluster traffic stays within the same zone, reducing cloud spend. Of course, the same availability-maximizing guarantees are provided for this traffic, and cross-zone traffic will be temporarily enabled if necessary to preserve system reliability.